[ crosspost su VoIT ]
Qualche idea innovativa per esplorare le potenzialita’ di avere dati in un formato versatile come RDF…
E qualche idea divertente, tipo questa:
-> RDFRoom! VIRTUAL REALITY IS NOW!
A lone soldier has been stranded in an alien world, filled with resources, literals and shifty anonymous nodes. Room upon room are filled with named graphs – can he find a way out?
Una vera forza della natura, a mio avviso…
Appena trovo un po’ di tempo, do’ un’occhiata al codice…
Look at some RDF DATA, schemas dont work well just now.
- Yes i know the fire effect is badly aligned.
- You need data with rdfs:seeAlso links to get doors.
Interpretare i links attraverso rdfs:SeeAlso come porte, e’ una vera forza: apre nuove strade per navigare nei nostri dati…
If I could put my files in a 3D world I know well – I would always remember that the PDF of my CV goes under the stair by the rocket launcher, and last year’s tax-returns go with the mega-health.
Qualche altra riflessione su quanto sia importante e relativo il modo di visualizzare dati RDF, tematiche a me molto care…
-> Visialize your RDF files, visualize your contact network
Per chiudere, una interessante vista molto simile al Tabulator di Tim Berners Lee:
-> OINK
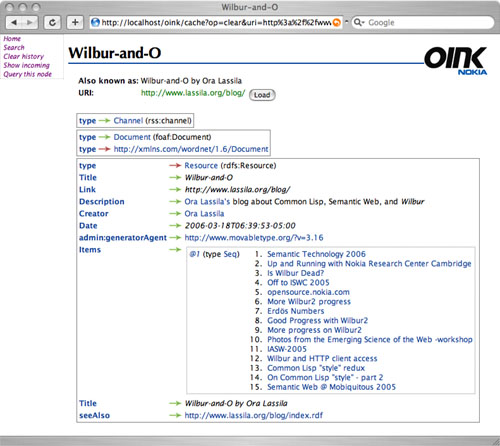
Oltre a questa interessante presentazione di Tim Berners Lee:
-> Browsable data
